Aujourd'hui pour changer un peu nous allons parler technique. Il ne vous aura pas échappé si vous suivez ce blog que je suis informaticienne, et c'est tout logiquement que nous allons parler de trucs liés aux ordinateurs.
Je me dois de préciser que je ne suis pas très bonne avec l'ordinateur (parce que, soyons honnêtes, ça ne m'intéresse pas), ce qui fait que je ne vais pas trop rentrer dans le détail ou des trucs trop compliqués, je ne fais pas des choses pour accomplir des prouesses. En revanche, quand je cherche à faire un truc précis avec un ordinateur, j'ai souvent suffisamment de jugeote pour arriver à mes fins, quitte à chercher de la documentation exotique en ligne.
Avant d'entrer dans le vif du sujet, une image d'un jeu que j'ai développé et que je n'ai jamais fini. J'en parlerai peut-être un jour.
L'objectif du jour sera d'apprendre à récupérer des données de façon industrielle sur le net. Nous utiliserons pour ce faire comme exemple le cas de KHInsider.
KHinsider est une des plus grosse librairie libre de mp3 d'OST de jeux-vidéo. Le soucis est que pour télécharger un album entier il faut posséder un compte, et nous ne voulons pas nous créer de compte. Dans le cas contraire, on ne peut télécharger qu'une chanson à la fois, en se rendant sur la page qui la contient plutôt que sur celle de l'album. Nous allons donc voir comment contourner ce problème en automatisant le processus de téléchargement.
En premier lieu, comment va-t-on procéder ? On connait la page de l'album, et cette page contient le lien de chaque page contenant une chanson. Or chacune de ces sous-pages possède exactement la même nomenclature. Il apparaît donc assez logiquement qu'un processus d'automatisation va être relativement simple. Nous allons voir comment.
Tout d'abord, posons une question plus pratique : comment récupère une donnée de façon automatique ? Et bien, pour cela, il nous faut l'emplacement du fichier, à partir de son URL. Comme nous pouvons le déduire de notre réflexion précédente, cette URL se trouve toujours au même endroit de la page qui contient la chanson, sous la forme http://khinsider/album/chanson.mp3. Une simple lecture par Ctrl + U du code HTML d'une de ces pages nous donne l'emplacement de cette ligne (ligne 179 à l'heure actuelle).
Dès lors, comment allons-nous procéder ? Il existe plein de solutions possibles, mais nous ferons le choix d'utiliser PHP. Pour utiliser PHP, il nous suffit d'avoir Apache que l'on peut trouver de base dans une solution LAMP (sous Linux, pour Windows c'est WAMP et Mac c'est XAMP) qui permet en plus de gérer une base de données, toujours utile. Une fois celui-ci correctement configuré, nous commencerons par créer un formulaire simple. Nous y renseignerons les seuls paramètres variables de la recherche. Quels sont-ils ?
_ http://khinsider/ : cette partie est fixe, il n'y a rien besoin de faire pour l'obtenir.
_ album : c'est la page qui regroupe les pages des pistes. Une simple lecture permet de l'acquérir.
_ chanson.mp3 : cette partie s'obtient en deux temps. D'une part, il faut obtenir l'URL de la page sur laquelle il se trouve, puis la ligne de cette même page où se trouve le nom de la piste. On a vu que la ligne est toujours la même, on va donc se concentrer sur la position de l'URL de la page.
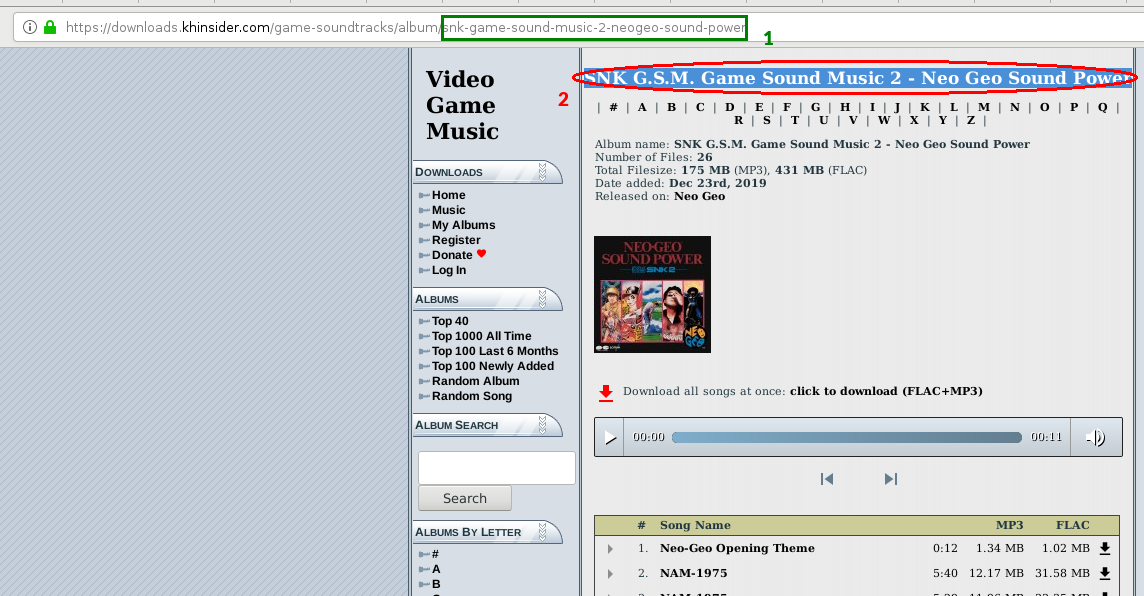
Voilà comment cela se présente sur la page d'album. 1. est le nom de la page l'album et qui fait partie de l'URL. 2. est le nom de l'album, qui nous sert juste à créer le dossier que l'on récupérera à la fin.
Une analyse de plusieurs pages d'albums via Ctrl + U nous informe que la position de la page de la 1ère piste n'est jamais la même, MAIS que l'écart entre deux URL est constant pour un même album. On va donc devoir récupérer deux informations :
_ Le numéro de la ligne sur laquelle se trouve l'URL de la 1ère piste;
_ Le pas, c'est-à-dire le nombre de ligne d'écart entre chacune des pistes pour cet album.
Dès lors, pour récupérer toutes pages de pistes et par conséquent des pistes, il nous suffit de récupérer les informations suivantes :
_ Le nom de l'album : on le connaît de base via l'URL de l'album;
_ La ligne de la 1ère piste : une lecture par Ctrl + U avec une recherche par Ctrl + F nous l'indique facilement;
_ Le pas : en partant de l'URL de la 1ère piste, simplement chercher celui de la 2nde (toujours par Ctrl + U) et calculer la différence.
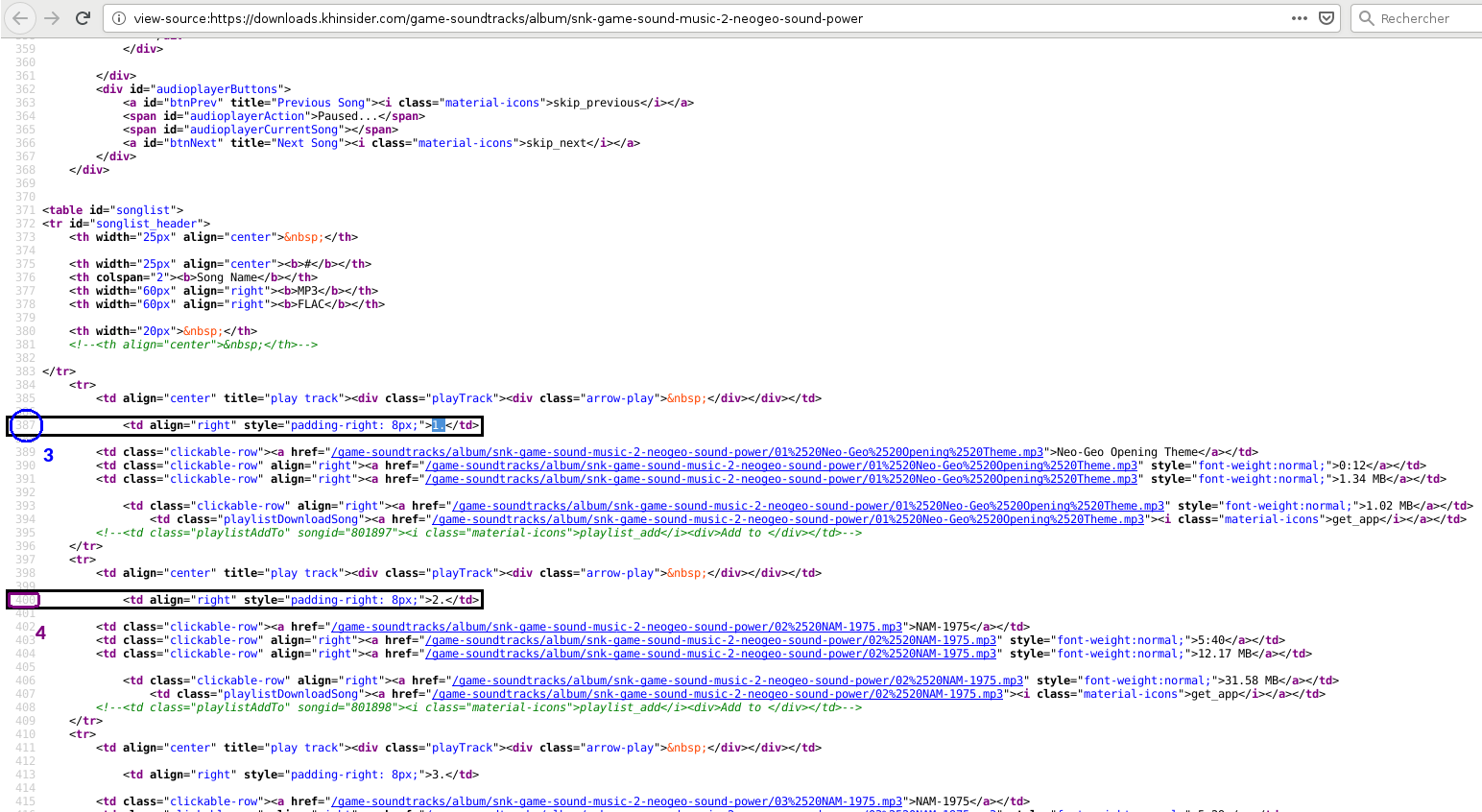
Le code HTML de la page de l'album obtenu par Ctrl + U, où on récupère l'emplacement des lien hypertext des pistes 1 et 2 de l'album. On les repère facilement grâce au "1." et au "2." de ces lignes (en utilisant Ctrl + F).
On va donc maintenant pouvoir créer une petite application qui permettra de faire la recherche automatique à partir de ces seuls paramètres. Nous allons donc commencer par faire un simple formulaire qui récupérera ces trois éléments. Cela se présentera sous la forme suivante :
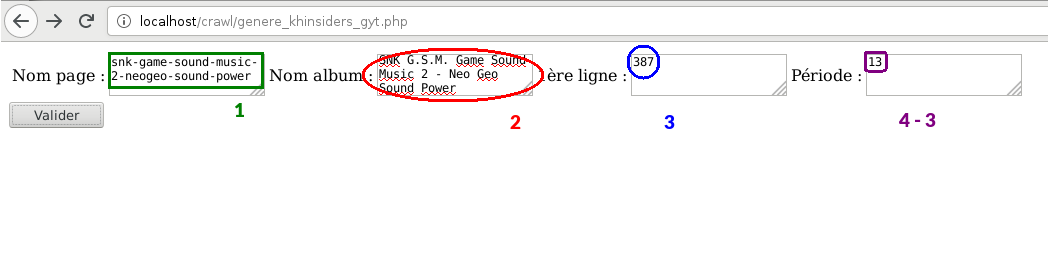
Le formulaire dans lequel on rentre les 4 paramètres que nous avons ainsi récupéré.
Le programme en lui-même est assez trivial, je mets juste à titre indicatif la boucle principale.
Voici le code de la boucle principale, qui représente l'essentiel du code. A noter que ce qui est en bleu est du commentaire et n'est pas exécuté par le programme.
Il y a évidemment un grand nombre de subtilités que je n'ai pas abordé, comme par exemple le découpage des lignes en petits morceaux pour récupérer les bouts qui nous intéressent; mais cela n'était pas l'objet de cet article. Le but ici n'était que de vous indiquer comment aborder une problématique relativement simple et comment la résoudre en employant une solution pas nécessairement très élaborée. Néanmoins si vous désirez plus d'explications sur la marche à suivre n'hésitez pas à me contacter sur Mastodon ou Twitter.
Sur ce, abordez des problèmes grâce à la puissance de l'informatique et amusez-vous bien.