Mon mémoire sur les typologies de bases de données
Pour changer un peu j'ai décidé de publier un document un peu plus scientifique qu'à l'accoutumée, à savoir mon mémoire de fin d'étude. Je le juge comme étant pas très technique, survolant pas mal en sujet son sujet mais je vous laisse juges. J'ai viré seulement les pas très intéressants comme la biblio, les remerciements et le sommaire. Ah et ayant été produit il y dix ans, le document présente certaines informations un peu datées.
Quelles sont les typologies de Systèmes de Gestions de Bases de Données existantes ?
Mémoire de fin d’étude
Introduction
L'avènement de l'informatique a été une étape importante dans la conservation et le traitement de l'information. Cette avancée a été due notamment à l’augmentation de la puissance de calcul des ordinateurs permettant d'exécuter des tâches toujours plus complexes, ainsi que dans la grande capacité de stockage de données de ces machines.
Les informations ont d'abord été stockées à l'intérieur de différents fichiers triés selon plus ou moins de rigueur par leurs utilisateurs. Si cette méthodologie était applicable lors des premières années de l’informatique, elle présenta rapidement ses limites. En effet, le nombre d’utilisateurs par machine connût une rapide expansion, notamment dans les administrations. Cependant, les données étant toujours centralisées en dépit de cette augmentation d’utilisateurs, il fallut rapidement établir des règles de gestion de l'information afin de simplifier sa manipulation.
C'est dans cette perspective que naquirent les bases de données. Ces bases de données constituent des collections de données qui présentent un certain nombre de principes destinés à en assurer la cohérence, la non-redondance et la pérennité des informations, en dépit d'un nombre de consultations simultanées en nombre important. Cependant, les données ne sont plus directement consultables comme c'était le cas lorsqu'elles n'étaient que simplement répertoriées dans des fichiers, mais nécessitent désormais d'être accédées par des Systèmes de Gestion de Bases de Données (SGBD), obligeant l'utilisateur à se servir d'une interface pour communiquer avec elles.
Il existe un grand nombre de SGBD ayant un certain nombre de propriétés différentes. Les caractéristiques inhérentes à ces SGBD dépendent bien souvent de choix conceptuels d’organisation et de représentation des informations. Ces choix auront un grand impact dans les traitements que nous pourrons effectuer sur les données contenues dans ces bases et donc sur l’agencement global de la SGBD. Dès lors, les principaux types de typologies des bases de données existantes seront ici étudiés, au niveau de leurs spécificités, afin de dégager les contraintes qui conduisent au choix d’une typologie plutôt qu’une autre.
Il sera d’abord question des systèmes de gestion de bases de données relationnels, reposant sur des concepts ensemblistes qui, par le nombre de ses représentants, représentent une part très importante du marché des systèmes de gestion de bases de données et rend donc leur analyse incontournable dans la présente étude. Cette étude portera ensuite sur les systèmes de gestion de bases de données orientés objet qui n’ont pas tenu toutes leurs promesses mais qui ont présagés les systèmes de gestion de bases de données orientés objet-relationnel qui est un modèle intermédiaire dont il sera ensuite question. Enfin, le cas des modèles de systèmes de gestions de bases de données plus exotiques sera abordé à travers le cas des systèmes de gestions de bases de données natif XML qui est un de leur représentant.
I/ Système de Gestion de Base de Données Relationnels
A/ Présentation
Les Systèmes de Gestion de Base de Données Relationnels – ou SGBDR – sont les SGBD les plus répandus à l'heure actuelle, aussi bien dans la variété des produits proposés que dans la proportion de SGBD de ce type en service actuellement.
Ces SGBD reposent sur une représentation des données sous un format Entité-Association. On distinguera la représentation logique de sa mise en application dans le cadre des SGBDR.
B/ Modèle logique
La représentation logique des données dans les SGBDR s'appuie grandement sur la théorie des ensembles en mathématique. Cette discipline des mathématiques étant à la fois vaste et très complexe, nous nous contenterons ici d'en exposer les prémisses qui ont une influence véritable dans l'élaboration du modèle relationnel.
Ainsi, distinguons les notions fondamentales de cette théorie que l'on retrouvera dans cette modélisation.
- Ensemble : un ensemble est une collection d'objets non-ordonnés et distincts. Ces objets partagent un certain nombre de caractéristiques. La possession de l'intégralité de ces caractéristiques est ce qui distingue un ensemble d'un autre. Ainsi, on aura par exemple un ensemble A qui sera composé d'éléments possédant les caractéristiques a1, a2, a3 ; et un ensemble B composé d'éléments ayant pour caractéristiques b1, b2 et b3. Les triplets (a1 ; a2 ; a3) et (b1 ; b2 ; b3) ne pourront être égaux sinon les deux ensembles seraient confondus, mais il n'existe aucune autre contrainte sur la composition des-dits triplets.
- Entité : Une entité est un objet donné d'un ensemble. Elle possède toutes les caractéristiques de l'ensemble à laquelle elle appartient. Deux entités d'un même ensemble étant distinctes, elles ne peuvent avoir toutes leurs valeurs égales deux à deux.
- Relation : Une relation est une propriété commune à deux entités données.
C/ Mise en application
L'application de cette théorie dans la modélisation des données dans le modèle Entité-Relation se fait de la façon suivante :
- La donnée unitaire informative est représentée sous forme d'entité. Les différentes valeurs des attributs de cette donnée sont les caractéristiques de cette entité.
- Les ensembles sont représentés sous forme de tables, dont les attributs forment les caractéristiques de cet ensemble. Ces tables possèdent un certain nombre de lignes, dont chacune d'entre elles contient les valeurs de chacune de ses entités. L'ensemble minimum des attributs permettant l'identification des éléments constituant cet ensemble s'appelle la clef primaire. En pratique, on consacre généralement un attribut de la table uniquement pour constituer cette clef primaire, simplifiant son utilisation.
- Les relations sont également stockées dans des tables. Ces tables sont réservées uniquement à l'usage des relations. Ces relations sont stockées sous forme de tuples contenant les clefs primaires des entités qu'elles relient : on parle dans ce cas de clefs étrangères.
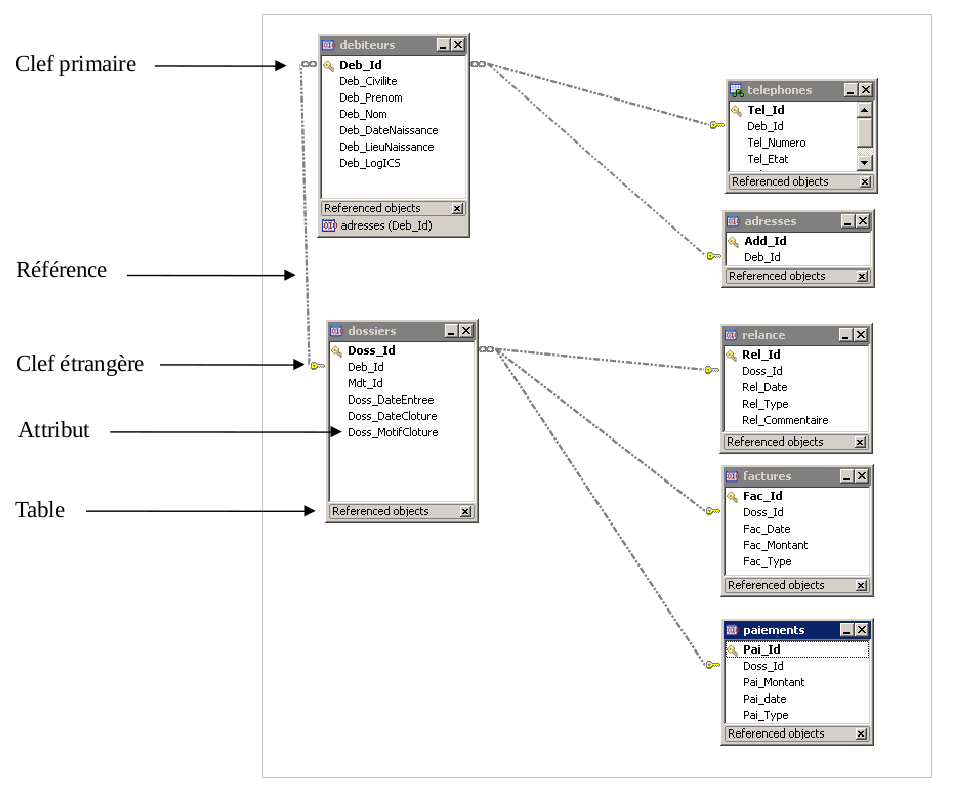
Exemple de représentation de modélisation Entité-Relation
D/ Apports
Le principal intérêt de l'utilisation du modèle Entité-Relation est l'usage de l'algèbre relationnel permettant de travailler sur des ensembles.
Il repose sur l'utilisation des opérateurs relationnels, eux-mêmes basés sur les opérateurs ensemblistes de base suivants :
- Union : l'union de deux ensembles forme un ensemble constitué de toutes les entités constituant ces deux ensembles.
- Intersection : l'intersection de deux ensembles forme un ensemble constitué de toutes les entités communes à ces deux ensembles.
- Différence : la différence de deux ensembles forme un ensemble constitué de toutes les entités d'un des deux ensembles non présents dans le second. Contrairement à l'union et l'intersection, la différence n'est pas symétrique et donc pour deux ensembles A et B donnés, A – B n'est pas nécessairement égale à B – A.
- Produit Cartésien : le produit cartésien est la matrice de deux ensembles donnés. Ainsi, si A = {a1 ; a2} et B = {b1, b2} deux ensembles, leur produit cartésien sera AxB = {(a1, b1) ; (a1, b2) ; (a2, b1) ; (a2, b2)}.
Les différents opérateurs relationnels sont constitués de la combinaison de ces différents opérateurs ensemblistes. Ces opérateurs sont utilisés dans des requêtes, qui permettent la récupération de données souhaitées. Les principaux opérateurs relationnels sont les suivants :
- Sélection : Définit l'ensemble des entités sur lesquelles la requête va porter.
- Projection : Définit les attributs des entités sélectionnées que l'on souhaite récupérer.
- Jointure : Fusionne des ensembles, éventuellement en ne sélectionnant que les entités ayant des similitudes.
Ces opérateurs sont implémentés dans le langage SQL (Structured Query Language), qui présente d'autres fonctionnalités que celles présentées ici (notamment le renomage ou la suppression de données, attributs, tables ou autres).
E/ Avantages
Les SGBDR répondent ainsi fondamentalement à trois grandes problématiques de la gestion de données :
- Manipulation de grandes quantités d'informations, au travers de sa modélisation ensembliste et du langage SQL;
- Cohérence des données, en empêchant la redondance et en assurant l'intégralité référentielle au moyen de contraintes fortes sur respectivement les clefs primaires et clefs étrangères : on peut par exemple décider que la suppression d’une entité entraîne la suppression de toutes les autres entités dont une clef étrangère est la clef primaire de l’entité initialement supprimée ; empêchant ainsi la présence d’entités référençant une entité inexistante. Il existe d’autres règles assurant l’intégrité et plusieurs manières de résoudre ces problèmes;
- Indépendance du mode de stockage des données et de la description de son état grâce à la modélisation entité-relation, permettant ainsi de modifier la structure de la base de données sans altérer les programmes la manipulant.
F/ Inconvénients
Néanmoins, les SGBDR présentent un certain nombre d'inconvénients :
- Les bases ne peuvent être maniées qu'à l'aide du langage SQL, qui ne s'avère pas suffisant pour l'élaboration d'une application entière, puisqu'il ne permet que la manipulation de la base. Du coup, nécessité de coupler à d'autres langages, comme PHP ou Java, par exemple, pour la partie applicative ;
- Le stockage des relations dans des tables augmente artificiellement le volume de données stockées.
- Le format de modélisation oblige de pouvoir représenter les données sous forme tabulaire, ce qui n’est pas forcément toujours le plus adapté. De plus, des objets définis de façon récursive ne peuvent pas être contenus dans ces tables. De la même façon, des données complexes comme des images ou des vidéos sont difficiles à stocker dans de telles bases.
- Impossibilité d’encapsuler les données, celles-ci étant totalement séparées du traitement. L’encapsulation consistant à masquer les informations permettant le fonctionnement d’un processus, son absence rend la lecture et la compréhension des données inutilement complexes pour un utilisateur non-averti.
G/ Applications utilisant les SGBDR
Les SGBDR sont le type de SGBD le plus répandu du marché. Cela s’explique notamment par la facilité d’utilisation du langage SQL qui fait sûrement des SGBDR les SGBD les plus simples d’accès.
Dans les types d’applications utilisant des SGBDR, on remarquera notamment les systèmes d’informations de type OLTP – pour OnLine Transaction Processing. Comme leur nom le suggère, ces applications interagissent avec la base de données de l’application en temps réel. Les volumes de données mis en jeu sont de moyenne importance, n’excédant pas le Go. L’application effectue un nombre fréquent de requêtes sur la base, mais rapides et courtes.
La majorité des applications constituées en dehors des grandes institutions (entreprises ou administrations) emploient des SGBDR, car il existe une offre très importante de SGBDR Open Source.
H/ Quelques SGBDR reconnus
Dans le cadre des SGBDR populaires, on pourra distinguer deux familles principales : les SGBD nécessitant une licence, et les SGBD Open Source.
Parmi les SGBD nécessitant une licence, les plus connus sont certainement Microsoft SQL Server, ne fonctionnant que sur des OS Windows, et les bases Oracles. A elles deux, ces deux licences représentent presque la moitié du marché du SGBDR.
Dans les SGBDR Open Source, le plus connu est de loin MySQL. C’est un SGBD beaucoup moins complet que les SGBD propriétaires, mais ses fonctionnalités sont plus que suffisantes pour les organisations de petites et moyennes tailles ; et sa simplicité d’utilisation et d’installation – notamment dû pour ce dernier point au fait qu’il soit couplé avec le serveur Apache et l’utilitaire PHPmyAdmin dans les packs WAMP et XAMP, en font un instrument très prisé par ces organisations.
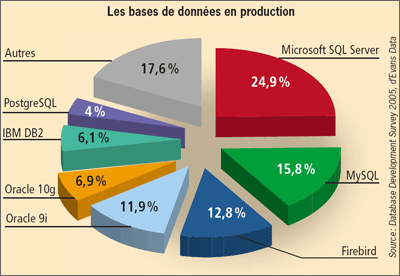
Part de marché des SGBDR en 2005
I/ Synthèse d’observation
Les SGBDR sont simples d’utilisation ; en l’absence de contraintes particulières, ils semblent être un excellent choix, comme tend à prouver la composition actuelle du marché des SGBD, majoritairement dominé par la présence des SGBDR. Il convient toutefois de noter que les SGBDR ne sont pas auto-suffisants d’un point de vue applicatif et qu’il est nécessaire d’ajouter une surcouche pour les utiliser, complexifiant légèrement leur usage.
II/ Systèmes de Gestion de Bases de Données Orientés Objet
A/ Présentation
Apparus au cours des années 1960 et popularisés aux cours des années 1980, les Systèmes de Gestion de Bases de Données Orientés Objet – ou SGBDOO - ont été créés dans la perspective de résoudre un certain nombre de problèmes inhérents à la représentation Entité-Associations des données. Comme pour les langages Orientés-Objets, tels Java ou C++, les données sont représentées de façon unitaire en tant qu’objet. Intéressons-nous quelques instants aux principes fondamentaux de la programmation orientée objet.
B/ Modèle logique
La représentation logique des données dans les SGBDOO repose sur les préceptes de la programmation orientée-objet. La programmation orientée-objet est un paradigme de programmation qui consiste à modéliser un problème en le ramenant à une représentation abstraite simplifié de ce problème, ne conservant que les données porteuses de sens de ce problème. Cette modélisation est possible grâce à la définition d’un certain nombre de concepts et l’élaboration de principes dont ne seront définis ici que ceux ayant une application concrète dans la modélisation des SGBDOO.
- Classe : ensemble des objets partageant un ensemble d’attributs.
- Instance : objet donné d’une classe, dont les valeurs des attribues sont toutes instanciées.
- Héritage : une classe héritant d’une autre possède tous les attributs et méthodes de la classe dont elle hérite, et peut en posséder d’autres. On qualifiera la classe héritant des méthodes et attributs de classe fille, et la classe servant de base de classe mère. Selon les modèles, il est possible ou non d’hériter de plusieurs classes simultanément.
- Polymorphisme : les propriétés héritées d’une classe mère par une classe fille peuvent être redéfinies dans cette dernière.
- Méthode : fonctions spécifiques à une classe ne pouvant être appelées que sur une instance de cette classe.
- Encapsulation : les valeurs des attributs d’une instance d’une classe ne sont connues que par cette instance, et ne peuvent ainsi pas être altérées ou consultées par un autre objet. Le niveau d’accessibilité de ces paramètres peut être plus ou moins souple selon le niveau de visibilité accordé. Puisqu’il est impossible d’accéder aux attributs depuis l’extérieur de cet objet, on peut définir des méthodes qui permettent d’outrepasser cette interdiction.
Ces différentes contraintes permettent une modélisation plus proche de la réalité des objets. Prenons par exemple le cas de la Classe Humain, possédant les attributs nom et âge. Soit une instance Jean ayant 24 ans. Dans la vie de tous les jours, il est impossible de connaître le nom et l’âge de cette personne au premier abord ; cet état de fait est ici retranscrit par la privatisation des attributs de cette instance. Si on voulait connaître ces informations dans le monde réel, nous serions contraints de demander à cette personne de nous les dire. On représente ce fait à l’aide de fonctions demanderAge ou demanderNom appelées directement sur Jean qui nous retourneraient alors ces valeurs – il sera toutefois nécessaire que ces deux fonctions aient été définies dans la classe Humain.
C/ Mise en application
L'application de cette théorie dans la modélisation des données dans le modèle Orienté-Objet se fait de la façon suivante :
- Une donnée unitaire est stockée sous forme d’objet. Un objet possède des attributs comme l’entité du modèle Entité-Relation. Cependant, contrairement à celle-ci, il possède un identifiant propre indépendant des données qu’il contient.
- La façon dont l’objet est stocké dans la mémoire est directement dépendante du langage utilisé dans le SGBDOO considéré. Il en est de même pour les classes ;
- Les objets ayant un identifiant propre, les valeurs de leurs attributs peuvent être toutes égales deux à deux. On considère que la non-redondance des informations doit être effectuée au niveau applicatif et non du modèle.
D/ Apports
La modélisation Orientée-Objet présente plusieurs avantages :
- Les données étant stockées sous forme d’objets, elles peuvent être directement exploitées par des applications écrites dans le même langage que celles-ci, évitant l’utilisation de connections.
- Certains SGBDOO permettent l’utilisation des méthodes de classe de l’objet pour altérer directement la base de données elle-même.
- L’encapsulation cachant la complexité des objets, on peut très facilement composer les objets. La composition d’objets consiste à assembler des objets ensemble pour représenter un objet plus complexe. Par exemple, on peut assembler des objets de classe Page et Couverture pour constituer un objet de classe Livre qui possédera l’ensemble des caractéristiques des objets composés. Dans le cas présent, le poids de l’objet Livre sera la somme du poids de toutes les Page et Couverture le constituant.
- Les SGBDOO peuvent transférer une partie du traitement sur la machine cliente pour réduire la charge de calcul des serveurs.
- De manière générale, les SGBDOO bénéficient avantageusement de la majorité des concepts de la modélisation Objet (héritage, polymorphisme, encapsulation, etc.).
E/ Inconvénients
Néanmoins, les SGBDOO présentent certains inconvénients :
- Ces SGBD n’ont pas connu un véritable succès commerciale et sont donc peu utilisés dans le commerce, il est ainsi assez difficile de trouver de la documentation traitant de problèmes relatifs à leur utilisation.
- L’absence de véritable standard ou norme réduit la possibilité d’expansion de ce type de SGBD.
- Ils sont difficiles à optimiser sans connaissance de l’implémentation des objets – c’est-à-dire la structure exacte des objets
- OQL, le langage de requête sur des objets est bien moins complet que SQL. La compatibilité des SGBDOO avec SQL est généralement faible.
F/ Applications utilisant les SGBDOO
Les SGBDOO sont conçus pour créer des objets polymorphes et composites. Les applications mettant à contributions ce type de SGBD sont majoritairement des applications utilisant des objets complexes, principalement des outils d’ingénierie, que ce soit en termes de génie logiciel, conception assistée par ordinateur ou des systèmes d’informations complexes comme les données géographiques.
G/ Quelques SGBDOO reconnus
La part du marché du SGBDOO est très minoritaire dans le monde du SGBD. Cependant, les SGBDOO les plus répandus sont des licences d’Oracle, Microsoft, IBM et Informix. Etant donné leur absence d’écho, on peut supposer que leur relatif succès repose majoritairement sur le fait d’appartenir à des acteurs majeurs du marché.
H/ Synthèse d’observation
Les SGBDOO ne sont pas fondamentalement moins efficaces que les SGBDR dans le traitement des données, possédant des atouts que ces derniers n’ont pas et réciproquement. Cependant, leur arrivée relativement tardive sur un marché entièrement acquis à la modélisation Entité-Relation, une compatibilité assez médiocre avec les bases de données ER et un faible investissement de la part des éditeurs dans ce domaine ont condamné l’utilisation de ces SGBD à un marché extrêmement spécifique dont rien ne laisse à penser qu’ils en sortiront dans un avenir plus ou moins proche.
III/ Systèmes de Gestion de Bases de Données Objet-Relationnel
A/ Présentation
Les Systèmes de Gestion de Bases de Données Objet-Relationnel – ou SGBDOR – sont, comme leur nom le suggère, des SGBD intermédiaires entre les SGBDR et les SGBDOO.
B/ Modèle logique
Les concepts abordés ici étant les mêmes que ceux des SGBDR et SGBDOO – modèle Entité-Relation et modèle Orienté-Objet, nous ne reviendrons pas dessus.
Néanmoins, il convient de noter qu’il existe deux approches symétriques des SGBOR : soit des SGBDR auxquels on étend certains concepts objet ; soit des SGBDOO permettant une modélisation Entité-Relationnel des données via un mapping Objet Relationnel.
C/ Apports
Globalement, les SGBDOR tentent de concilier les points forts et les points faibles des deux méthodes, dans des compromis qui varient d’un SGBOR à un autre. Cependant, ils présentent généralement tous les avantages suivants :
- Possibilité d’utilisation de requêtes SQL.
- Possibilité de programmer des applications de façon native.
- Possibilité de programmer d’un point de vue applicatif sans se soucier de l’implémentation SQL.
A l’opposé, ils doivent généralement affronter une certaine complexité d’utilisation liée à la difficulté des outils utilisés pour assurer la compatibilité entre les deux modélisations possibles de la base de données.
D/ Synthèse d’observation
Les SGBDOR ne sont à l’heure actuelle pratiquement qu’à l’état expérimental, l’un des rares SGBDOR reconnu demeure PostgreSQL. Cependant, il représente à lui seul plus de 15% du marché Open Source du SGBD et 5% du marché du SGBD. On peut spéculer qu’il représente un candidat sérieux dans la tentative d’arrêt de l’hégémonie du modèle SGBDR.
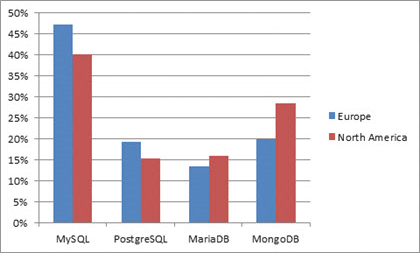
Part du marché des SGBD Open Source de certaines SGBD en Octobre 2011
IV/ SGBD Natif XML
A/ Présentation
Les Système de Gestion de Bases de Données Natifs XML – ou SGBD Natifs XML – sont des SGBD reposant sur le stockage de données au format XML.
B/ Modèle logique
Le XML – ou Extensible Markup Language - est un méta-langage de balisage. Il est utilisé pour la représentation de structures complexes, comme les arbres. Par son formalisme, il est capable d’exprimer une hiérarchisation entre les éléments d’un ensemble, et peut ainsi représenter tout type de données. Il est utilisé notamment pour l’échange de documents où cette spécificité se révèle très pratique.
Le XML en lui-même se structure en arbres. Ces derniers sont issus de la théorie des graphes. Intéressons-nous aux notions élémentaires de la théorie des graphes qui nous permettront de mieux appréhender la question.
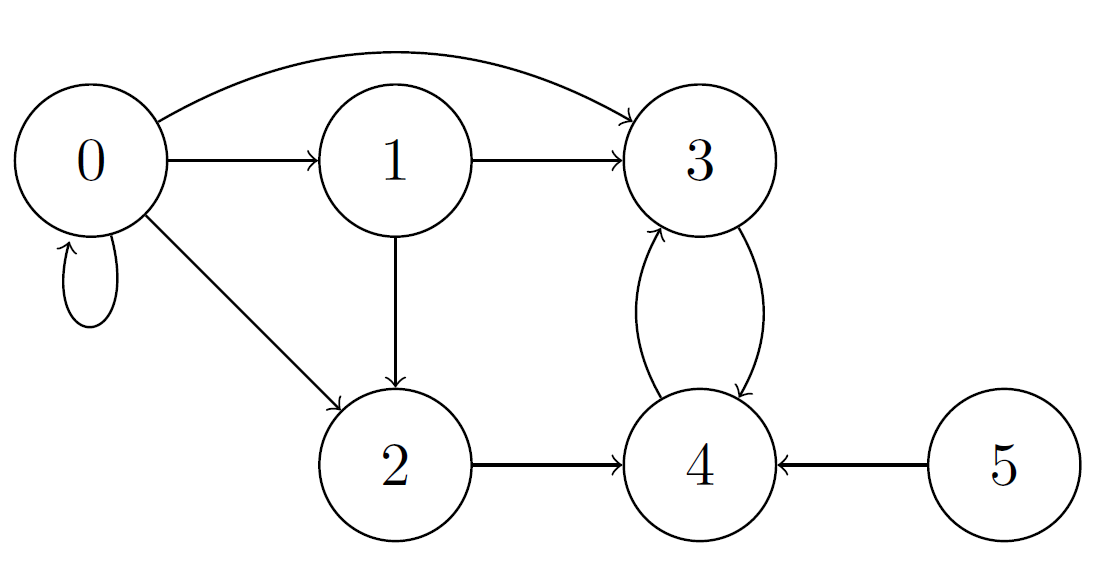
Exemple de graphe orienté
Un graphe est un ensemble de sommets dont certains sont liés deux-à-deux par une relation. Il existe deux représentations de graphe. Le choix de l’une ou l’autre influe sur le vocable utilisé.
La première représentation de graphe est le cas des graphes orientés. Dans cette représentation, la relation entre un sommet A et un sommet B allant de A vers B – que l’on représentera A -> B - n’est pas équivalente à la relation allant de B vers A – que l’on représentera B -> A. On dit que la relation de A vers B n’est pas symétrique à la relation de B vers A. Dans ce cas présent, les relations entre les sommets sont nommées des arcs.
La seconde représentation est le cas des graphes non-orientés. Dans cette représentation, la relation entre un sommet A et un sommet B allant de A vers B est équivalente à la relation allant de B vers A : on a représentera ainsi indifféremment A-B ou bien B-A. Ces deux relations sont équivalentes et donc symétriques ; mais il convient toutefois de noter que le graphe non-orienté est une simplification du graphe orienté dans lequel la relation A-B est équivalente aux relations A->B ET B->A. Dans le cas d’un graphe non-orienté, les relations entre les sommets sont nommées des arêtes.
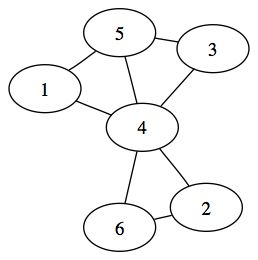
Exemple de graphe non-orienté
Un graphe à proprement parler est l’ensemble des sommets et des arcs/arêtes le définissant.
Un arbre est un type de graphe orienté présentant les propriétés suivantes :
- Un sommet ne dispose au plus que d’un seul sommet parent ; c’est-à-dire qu’il n’existe au plus pour un sommet B qu’un unique sommet A vérifiant A -> B.
- Un sommet peut être le parent de n’importe quel nombre d’autres sommets.
- Les sommets qui ne sont parents d’aucun autre sommet sont appelés des feuilles.
- Les sommets qui sont parents d’au moins un autre sommet sont appelés des nœuds.
- Il existe un unique sommet ne disposant d’aucun parent. Ce sommet est nommé la racine de l’arbre.
L’arbre est une structure de graphe qui possède par ces caractéristiques un certain nombre de propriétés intéressantes. Ainsi, en suivant les règles de construction de l’arbre, il est possible en partant de la racine de l’arbre de rejoindre n’importe quel autre sommet de l’arbre en suivant les relations liant les sommets entre eux.
L’arbre présente aussi la propriété d’être récursif. L’arbre est ainsi décomposable à chaque niveau de sa structure soit en une feuille ; soit en un nœud et un sous-arbre. Cette propriété permet l’application d’un bon nombre d’algorithmes intéressants sur l’arbre, notamment les algorithmes de parcours – qu’ils soient en profondeur ou en largeur.
L’arbre présente ainsi l’intérêt de permettre l’accès de façon unique à un élément depuis la racine à l’aide d’un accès optimal.
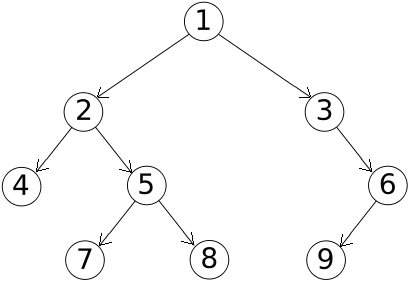
Exemple d’arbre
C/ Mise en application
L'application de cette théorie dans la modélisation des données dans le modèle XML se fait de la façon suivante :
- La donnée unitaire est contenue dans un élément. L’élément est la transposition du nœud de l’arbre dans le contexte de la structure XML. Les attributs de cette donnée sont contenus dans des balises de l’élément.
- La hiérarchisation de sommets parent-enfants se retrouve dans l’agencement du code XML. En effet, les entités peuvent contenir une infinité d’autres entités. Cependant, les entités doivent être strictement incluses les unes dans les autres, ce qui permet de retrouver l’idée que les entités n’ont qu’un seul parent (l’entité dans laquelle elles sont incluses), mais peuvent posséder autant d’enfants que voulu (toutes les balises qu’elles contiennent).
- La racine de l’arbre est quant à elle le point d’entrée du document XML, soit l’entité la plus externe. Il ne peut pas y avoir d’autre entité située au même niveau hiérarchique qu’elle, ce qui permet de vérifier l’unicité de l’entité n’ayant aucun antécédent.
D/ Apports
L’utilité première des SGBD Natifs XML est l’intégration de données de types XML. Les SGBDR – et les SGBD non XML Natifs en général - ont en effet beaucoup de difficultés à stocker les données du type XML. Ces SGBD ont deux approches différentes quant à la sauvegarde de ces documents.
La première approche consiste à stocker le document XML tel quel dans la base de données. Cette solution a le mérite d’assurer l’intégrité du document enregistré ; cependant, cette approche rend aussi difficile sa manipulation une fois ce document intégré à la base.
La deuxième approche consiste à décomposer le document dans une table prévue à cet effet. Bien que la manipulation de données soit grandement facilitée, cette méthode présente le grand inconvénient de ne pas assurer la conservation du document original, mais simplement une modélisation. Pour restituer le document d’origine, il faut ensuite faire appel à des requêtes complexes et un mapping de schémas XML depuis sa modélisation. De plus, par sa nature complexe et récursive, modéliser une table ER qui respecte systématiquement les contraintes des documents XML considérés peut s’avérer très complexe.
Les SGDBR Natifs XML stockent les documents en entier comme il l’a été décrit dans la première approche de stockage de SGBDR. Cependant, ces SGBD sont conçus pour pouvoir utiliser XQuerry, le langage de requêtes des documents XML de façon native sans avoir à charger le document depuis la base.
Certains SGDBR peuvent utiliser XQuerry sur les données XML qu’ils contiennent, mais il leur faut nécessairement pour cela soit effectuer une restitution du document d’origine, soit le charger directement.
E/ Synthèse d’observation
Le domaine du marché SGBD XML Natif recouvre un besoin extrêmement spécifique – la gestion des documents XML, besoin auquel répondent déjà partiellement des SGBD plus généralistes, édités par les plus grands acteurs du marchés – dont MySQL et PostgreSQL dans une moindre mesure, malgré une gestion assez incomplète – on peut donc se demander si ce type de typologie a véritablement un avenir dans un contexte où les solutions que cette typologie propose ne font pas parties du cadre de préoccupation de la majorités des usagers de SGBD.
V/ Conclusion
Nous avons examiné au cours de cette étude la typologie de la majorité des SGDB connus. Nous avons négligé l’étude d’un certain nombre de typologies existantes comme celle des SGBD hiérarchiques et réseaux car rendus obsolètes suite à l’introduction des SGBDR qui les a remplacés ; ou comme les SGBD déductives recouvrant des besoins beaucoup trop spécifiques pour s’inscrire dans le cadre de cette étude à caractère généraliste.
La revue des différents types de typologie que nous venons d’effectuer permet de conclure que la forte implantation du modèle Relationnel et sa grande facilité d’utilisation confinent toute autre typologie à des besoins très spécifiques auxquels les SGBDR ne répondent pas de façon suffisamment satisfaisante.
Cependant, le succès et les bonnes performances de PostgreSQL ainsi que le compromis intéressant qu’il apporte entre le modèle Relationnel et le modèle Objet laissent entrevoir à long terme dans les SGBDOR une alternative possible aux SGBDR.
